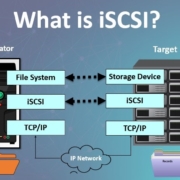
یک شبکه فضای ذخیرهسازی (SAN) اساساً مانند یک هارددیسک خارجی عمل میکند، با این تفاوت که هارد اکسترنال بهشدت کنترل میشود، به یک شبکه متصل است و میتواند توسط چندین دستگاه استفاده شود. اما این سؤال پیش میآید که چگونه درایوهای ذخیرهسازی را در یکSANبه کامپیوترهای سراسر شبکه متصل می کنید؟
پروتکل Fiber Channelچیست؟
پروتکل Fiber Channelیک ابزار خیلی خاص صرفاً برای ذخیرهسازی در نظر گرفتهشده است. به طور خاص، پروتکل کانال فیبر فقط از پیام رسانی SCSI پشتیبانی می کند. SCSI یک رابط است که برای اتصال و ارتباط با درایوهای ذخیرهسازی در رایانه استفاده میشود. شما احتمالاً فقط درایوهای SCSI را در سرور پیدا خواهید کرد، اما آنها را میتوان در ماشینهای با کارایی بالا نیز یافت.
پروتکل Fiber Channelاز رسانه فیبر نوری برای انتقال پیامهای SCSI از طریق شبکه استفاده میکند. اینیک پروتکل SCSI با سرعتبالا و متصل به شبکه است.
بین پروتکل Fiber Channelو شبکه سنتی مبتنی بر اترنت شما تفاوت هایی وجود دارد. به عنوان مثال، پروتکل کانال فیبر از اتصال اترنت، IP، TCP یا UDP استفاده نمی کند. فریم ها (یا بسته ها) از طریق اترنت نیز ارسال نمی شوند.
پروتکل Fiber Channel، stack مخصوص به خود را دارد. فریمها نیز کمی متفاوت از فریم اترنت سنتی شما هستندHeader . در فریم پروتکل Fiber Channel، 24 بایت است. یک فضای header اختیاری اضافی نیز وجود دارد که اندازه آن 64 بایت است .درنهایت، بخش محموله فریم، 2048 بایت وزن دارد .در برخی موارد، فضای header اضافی و بخشهای محموله قاب باهم ترکیب میشوند.
FCoE ارسال فریمهای Fiber Channelرا از طریق شبکه اترنت با پوشش دادن فریمهای Fiber Channelدر داخل یک فریم اترنت تسهیل میکند.
آیا Fiber Channelبا سوئیچهای معمولی کار میکند؟
پروتکل Fiber Channelبا تجهیزات شبکه استاندارد سازگار نیست. پروتکل Fiber Chanel از اترنت، IP، TCP یا UDP استفاده نمیکند؛ بنابراین، تجهیزات شبکه استاندارد بیتهای موردنیاز برای پردازش ارتباطات برای Fiber Channelرا ندارند.
در عوض، شبکهها از تجهیزات خاصی که برای Fiber Channelساختهشده است استفاده میکنند. بهعنوانمثال، سیسکو یک سری محصولات به نام سوئیچهای MDS دارد. این سوئیچ ها همچنان با استفاده از NX-OS کار می کنند. بسیاری از دستورات مشابهی که بهطور معمول در یک سوئیچ استاندارد استفاده میشوند، برای مدیریت سوئیچهای MDS نیز استفاده میشوند. این سوئیچها از پروتکل Fiber Channel برای ارتباط استفاده میکنند.
گرهها یا سرورهای ذخیرهسازی از آداپتورهای رابط شبکه استاندارد نیز استفاده نمیکنند. در عوض، آنها از آداپتور باس میزبان استفاده میکنند. به نظر شبیه کارت شبکه فیبر نوری است اما بهجای آن از پروتکل Fiber Channelاستفاده
آدرس MAC یک شناسه خاص برای هر دستگاه الکترونیکی است که به نحوی از طریق یک شبکه ارتباط برقرار میکند. روترها، سوئیچها و حتی گوشی هوشمند شما دارای آدرس MAC هستند. آنها برای عملکرد یک شبکه مبتنی بر اترنت حیاتی هستند.
شبکههای Fiber Channel از آدرسهای MAC استفاده نمیکنند. بااینحال، آنها یک شناسه مشابه دارند. درواقع دو تا هستند. یکی WWNN یا نام گره جهانی نامیده میشود. دیگری WWPN یا نام پورت جهانی است. هر دو در دستگاهها تعبیه شدهاند و قابلتغییر نیستند. آنها به روشی مشابه آدرس MAC کار میکنند.
مانند همهچیزهایی که در رایانهها وجود دارد، پروتکل Fiber Channelمعمولاً بر روی دو قدرت عمل میکند. بهعنوانمثال، این پروتکل با سرعت انتقال 1 گیگابایت شروع شد، سپس به2 و بعد به 4 گیگ ارتقا پیدا کرد. امروز ما سرعت64 گیگابایت را برای Fiber Channel داریم و سرعت 128 گیگابایت بهزودی در دسترس خواهد بود.
پروتکل Fiber Channel خدمتی مفید در شبکه سازمانی مدرن امروزی است. Fiber Channelبه مدیران فناوری اطلاعات راهی میدهد تا حجم زیادی از ذخیرهسازی را به شیوهای کنترلشده تسهیل کنند. یادگیری Fiber Channelبرای هر شبکه یا sysadmin متعهد ضروری است.
برای هرکسی که نیاز به درک پروتکلهای مختلف موجود برای اشتراکگذاری ذخیرهسازی بلوک از طریق شبکه دارد، گزینه های زیادی وجود دارد. در ادامه به تفاوتهای بین آنها و اینکه چرا یک شخص یا سازمان در یک موقعیت خاص یکی را بر دیگری ترجیح می دهد، می پردازیم.
ذخیرهسازی تحت شبکه چیست و چرا از آن استفاده میشود؟
در روزهای اولیه محاسبات، دادهها اغلب بر روی رسانههایی مانند کارت پانچ، نوار مغناطیسی و فلاپی دیسک ذخیره میشدند. مسائل گوناگون رفاهی و قابلیت اطمینان با همه اینها وجود داشت. هنگامیکه هارددیسک توسعه یافت و محبوب شد، انواع مختلف اتصال تکامل یافت. اما در بیشتر موارد، این شامل یک سیستم کامپیوتری بود. فضای ذخیرهسازی و دادههای ذخیرهشده روی آن اساساً روی رایانهای که بهطور فیزیکی به آن متصل بود دنبال میشد. نقاط ضعف این مجموعه، دشواری دسترسی به دادهها از جاهای دیگر، علاوه بر اشغال بیشتر فضای دیسک است.
اختراع روشهای به اشتراکگذاری این ذخیرهسازی بین سیستمهای کامپیوتری به حل این چالشها کمک کرد. ذخیرهسازی شبکهای، تخصیص فضای دیسک در بلوکها را به چندین رایانه امکانپذیر میکند و استفاده از فضای دیسک گرانقیمت را بسیار کارآمدتر میکند. همچنین میتواند بهعنوانمثال، خوشهای از سرورهای پایگاه داده را فعال کند تا بهطور همزمان به همان دادهها دسترسی داشته باشند.
همچنین روشهایی برای اشتراکگذاری فایلها در شبکه وجود دارد که به آنهاNAS (Network Attached Storage) میگویند. اینیک استراتژی کاملاً متفاوت است که دارای پروتکلهای خاص خود مانند NFS، SMB و AFP است که خارج از بحث این مقاله است. در این مقاله، ما روی ذخیرهسازی «بلاک» تمرکز میکنیم که قسمت هایی از فضای دیسک است که به نظر میرسد سیستمعامل رایانه مانند یک هارددیسک متصل بهصورت محلی است.
SCSI چیست؟
SCSI نسل قبلی همه آنهاست. در گذشته روشهای مختلفی مانند SASI، SMD، ESDI، ST-506 و غیره برای اتصال دیسکهای سخت به رایانهها وجود داشت. بیشتر اینها اختصاصی بودند، یعنی توسط سازندهای مانند سیگیت یا آیبیام با قابلیت تعامل متقابل اندک یا بدون تعامل متقابل با سایر تجهیزات فروشنده توسعهیافته بودند.
پروتکل SCSI (رابط سیستم کامپیوتری کوچک) از SASI (رابط سیستمی Shugart Associates ) تکاملیافته و در سال 1986 به استاندارد ANSI تبدیل شد. این استاندارد به تولیدکنندگان متعددی این امکان را داد تا بهجای اینکه خریداران را مجبور به «lock in» با یک محصول شوند، محصولاتی را توسعه دهند که باهم کار کنند. این استاندارد بهنوبه خود باعث افزایش محبوبیت آن شد.
یک پیادهسازی زیرسیستم معمولی SCSI )معمولاً “skuz-ee” تلفظ میشود( شامل یک یا چند کنترلر (بردهای مدار با کانکتورهای کابل)، یک یا چند کابل روبان سیم مسی با چندین کانکتور دیسک سخت و مجموعهای از هارددیسک است. برخی از ویژگیهای اولیه SCSI مجموعه دستورات نسبتاً سادهای است که برای کنترل هارددیسکها استفاده میشود و تعداد دستگاههایی که میتوان به یک کنترلر متصل کرد (16 یا بیشتر). یکی از ایرادات این بود که طول کابل محدود پشتیبانی میشد، اما این مشکل در هارددیسکهای یک سیستم کامپیوتری بهندرت پیش می آمد.
درحالیکه این جنبههای فیزیکی یک زیرسیستم SCSI امروزه بهندرت در رایانهها استفاده میشود، پروتکل SCSI خود بهعنوان پایهای برای پروتکلهای جدیدتر مانند SAS (Serial Attached SCSI) و FC (کانال فیبر) ماندگاری پیداکرده است.
کانال فیبر (FC) چیست؟
کانال فیبر که بهاختصار “FC” نامیده میشود، در اواخر دهه 1980 توسعه یافت و در سال 1994 به یک استاندارد موسسه استاندارد ملی آمریکا (ANSI) تبدیل شد. همانطور که از نام آن پیداست، بر اساس کابلکشی فیبر نوری چندحالته نسبتاً جدید طراحیشده است. بهعنوان حملونقل فیزیکی، حداقل در سناریوهای دارای مسافت طولانیتر، برای غلبه بر برخی از محدودیتهای لایه فیزیکی SCSI. FC درواقع میتواند روی کابلهای مسی در فواصل کوتاه کار کند، اما محدودیتهای فاصله در فیبر نوری بسیار بیشتر است.
ازآنجاکه پروتکل SCSI بسیار محبوب و قوی بود، بهعنوان یک «پروتکل لایه بالایی» که در بالای FC بهعنوان پروتکل انتقال قرار داشت، پیادهسازی شد. بهعبارتدیگر، FC اتصال فیزیکی، رمزگذاری و انتقال دادهها مانند دستورات SCSI را از یک نقطه پایانی به نقطه دیگر مدیریت میکند . FC درواقع قادر به انتقال انواع دیگری از دادهها است، اما ما در اینجا برای ذخیرهسازی بلوک بر روی SCSI متمرکزشدهایم. یک شبکه FC دارای ویژگیهای ارائه تحویل بدون تلفات دادههای بلوک خام و همچنین تحویل «به ترتیب» بستهها است که هر دو قابلیت اطمینان و کارایی را بهبود میبخشند.
کانال فیبر به سختافزار طراحیشده خاصی نیاز دارد. سرورها باید یک پورت یا کارت “Host Bus Adapter” (HBA) داشته باشند و دستگاههای ذخیرهسازی نیز باید یک رابط FC داشته باشند که در این مورد اغلب بهعنوان یک پورت جلویی نامیده میشود. یک شبکه FC معمولاً بهعنوان SAN (شبکه منطقه ذخیرهسازی) نامیده میشود. تعدادی توپولوژی مختلف وجود دارد که یک FC SAN را میتوان برای استفاده از آنها پیکربندی کرد.
یک وضعیت معمولی شامل حداقل دو سوئیچ FC اختصاصی با چندین پورت فیزیکی است که هر سوئیچ نشاندهنده یک “Fabric” ازلحاظ فیزیکی جداگانه است و هر سرور یا دستگاه ذخیره حداقل یک اتصال به هر Fabric دارد. این ویژگیهای اضافی افزونگی و پتانسیل بهبود عملکرد را فراهم میکند. اگر سوئیچ، HBA یا کابل فیبر نوری از کار بیفتد، اتصال به حافظه قطع نمیشود. در موارد خاص، از اتصالات متعدد میتوان برای افزایش پهنای باند و توان استفاده کرد. کانال فیبر یک محیط بسیار غنی از امکانات است و مکانیسمهای مختلفی برای کنترل مواردی دارد، مثلاً اینکه کدامیک از آغازگرها میتوانند دستگاههای هدف را ببینند.
همچنین در اینجا شایانذکر است که توسعه FC SAN، طراحی دستگاههای بزرگ با هارددیسکهای زیاد را برای تولیدکنندگان امکانپذیر ساخت که عموماً به آنها «آرایههای ذخیرهسازی» میگویند. اینها معمولاً از یک روش حفاظت از دادهها مانند RAID (آرایه اضافی از دیسکهای ارزانقیمت) استفاده میکنند که میتواند گروههایی از هارددیسکهای فیزیکی را در آرایهها با چند کپی از دادهها یا یک برابری محاسبهشده که بازسازی دادهها را امکانپذیر میکند، ترکیب کند. اگر هارددیسک از کار بیفتد (که معمولاً با دیسکهای چرخان اجتنابناپذیر است)، میتوان آن را بهسادگی حذف و جایگزین کرد و دادهها روی درایو دوباره ساخته میشوند. فضای دیسک بهصورت دلخواه بین سرورهای SAN در واحدهایی به نام Logical Unit Numbers (LUN) تقسیم میشود. بنابراین میتوان از فضا بهطور بسیار مؤثرتر و پویاتر استفاده کرد.
در حال حاضر، سرعت FC تا 128 گیگابایت در ثانیه (128GFC) در دسترس است. بااینحال، رایجترین پیادهسازی در حال استفاده امروز 32 GFC، معمولاً با ترکیبی از دستگاههای کمسرعت در SAN است.
معایب کلیدی: FC SAN نتیجه کلی استفاده از FC SAN سیستمی است که بسیار قابلاعتماد، بسیار مقاوم در برابر خطا و بسیار گران است. کارتهای سرور HBA گران هستند، سوئیچهای FC و آرایههای ذخیرهسازی بسیار گران هستند و حتی کابلهای فیبر نوری که همه اینها را به هم متصل میکنند نیز ارزان نیستند.
پروتکل iSCSI چیست؟
پروتکل رابط سیستم های کامپیوتری کوچک اینترنت (iSCSI) برای استفاده از زیرساخت شبکه TCP/IP موجود برای انتقال دادههای ذخیرهسازی بلوک طراحیشده است. پیادهسازی iSCSI مانند FC بهعنوان SAN شناخته میشود، اما در این مورد بهطور خاص یک SAN iSCSI است. قابلیتها و محدودیتهای این فناوری از چند جهت با FC SAN متفاوت است.
پروتکل TCP/IP ترکیبی از» لایههای» ارتباطی پروتکل کنترل حملونقل (TCP) و پروتکل اینترنت (IP) است. این استانداردها توسط کارگروه مهندسی اینترنت (IETF) تأیید و نگهداری میشوند. این پروتکل اساساً بلوک ساختمانی است که بیشتر فضای اینترنت همانطور که میدانیم بر روی آن ساختهشده است. آدرسهای TCP/IP که برای هدایت بستههای داده از نقطهای در اینترنت به نقطه دیگر استفاده میشوند جنبهای است که اکثر ما با آن آشنا هستیم.
پروتکل iSCSI، به زبان ساده، دستورات SCSI است که دربستههای TCP/IP قرار داده شدهاند و سپس از طریق هر شبکه فیزیکی موجود ارسال میشوند. iSCSI بهعنوان یک استاندارد توسط IETF در سال 2004 تصویب شد. اولین مزیت آشکار برای iSCSI این است که اکثر سرورها قبلاً به یک شبکه اترنت متصل هستند و حداقل یک آدرس IP دارند. بسیاری از آرایههای ذخیرهسازی مدرن دارای قابلیت iSCSI هستند، بنابراین یک iSCSI SAN را میتوان درست بر روی یک شبکه موجود ساخت. دومین مزیت این است که نیازی به خرید سختافزار FC گرانقیمت و اجرای مجموعه دوم کابلهای فیبر نوری نیست.
برتری دیگر این روش این است که نیازی به یادگیری مهارتهای Fiber Channel نیست. شرکتی که شبکه اترنت دارد احتمالاً قبلاً دارای پرسنل بادانش شبکه است و راهاندازی iSCSI نسبتاً آسان است.
معایب کلیدی iSCSI در مقابل کانال فیبر :بااینحال، برخی از معایب مشخصی برای استفاده از iSCSI در مقایسه با FC وجود دارد. اول، TCP/IP دارای سربار پردازش ذاتی است که میتواند عملکرد و پهنای باند را کاهش دهد .اترنت
“in order” frame delivery را تضمین نمیکند که باعث میشود TCP تشخیص دهد که بستهها از بین رفته یا رها میشوند و آنها را مجدداً ارسال میکند. یکی دیگر از معایب، افزونگی استFC SAN :ها معمولاً با چندین HBA روی سرورها، Fabrics دوگانه ایزوله و چندین پورت هدف روی آرایههای ذخیرهسازی ساخته میشوند.
کانال فیبر از طریق اترنت (FCoE) چیست؟
شبکههای اترنت از اواسط دهه 1970 به شکلی وجود داشتهاند که در مرکز تحقیقات زیراکس پالو آلتو (PARC) اختراعشدهاند و فقط برای استفاده داخلی هستند. بااینحال زیراکس اجازه داد تا مشخصات عمومی منتشر شود و در سال 1983 توسط کمیته 802.3 موسسه مهندسین برق و الکترونیک (IEEE) بهعنوان یک استاندارد تأیید شد. از آن زمان به بعد، اترنت در دفاتر، مراکز داده و حتی بیشتر خانهها همهجا وجود دارد. سرعت از 3 مگابیت در ثانیه به 100 گیگابایت بر ثانیه و بالاتر افزایشیافته است.
FCoE یک استاندارد جدیدتر است که بخشی از استاندارد کمیته بینالمللی استانداردهای فناوری اطلاعات (INCITS) T11 FC-BB-5 است که در سال 2009 منتشر شد. اساساً این امکان را میدهد تا بستههای کانال فیبر بومی را در فریمهای اترنت قرار دهیم FCoE .نیاز به اصلاحاتی در شبکه اترنت دارد، اما اکثر سوئیچهای اترنت مرکز داده مدرن از آن پشتیبانی میکنند. برای سرورها، FCoE میتواند بر روی یک رابط اترنت «استاندارد» اجرا شود، اما عملکرد هنگام استفاده از یک آداپتور شبکه همگرا (CNA) بسیار مناسب تر است. ازآنجاییکه FCoE لایهای است که مستقیماً بالای لایه اترنت اجرا میشود و TCP/IP را شامل نمیشود، روی شبکههای غیر پیوسته قابل مسیریابی نیست.
مزایای کلیدی FCoE نسبت به کانال فیبر. مزایای FCoE نسبت به FC خالص در درجه اول در کاهش هزینه، عدم نیاز به خرید سختافزار اختصاصی FC و نه مهارتهای پیشرفته موردنیاز برای نصب و مدیریت آن است. معایب آن این است که با FCoE، ترافیک ذخیرهسازی از طریق شبکهای مشابه سایر ترافیکها ارسال میشود و مناقشه امکانپذیر است و تنها برخی از آرایههای ذخیرهسازی از FCoE بومی پشتیبانی میکنند.
مزایای کلیدی FCoE نسبت به: iSCSI مزایای FCoE نسبت به iSCSI عمدتاً عملکرد و قابلیت اطمینان است، بااینحال با یک شبکه اترنت بسیار سریع در هر دو مورد، تفاوت ممکن است فقط در موقعیتهای بسیار فشرده داده ظاهر شود. نقطهضعف FCoE (بسته به دیدگاه فرد) این است که هنوز به مهارتهای FC و سختافزار پیشرفته نیاز دارد.
کانال فیبر، FCoE یاiSCSI ؟ کدام یک مناسب تر است، چه زمانی و چرا؟ بنابراین چگونه میتوانیم تصمیم بگیریم که کدام را انتخاب کنیم؟ اولازهمه، در مواردی که روی یک datacenter قبلاً یک FC SAN نصب شده باشد ، اگر قدیمی و کند نباشد، توجیه تغییر از آن به یکراه حل مبتنی بر اترنت یا TCP/IP دشوار است. این وضعیت باوجود تجهیزات ذخیرهسازی که از پروتکلی غیر از FC پشتیبانی نمیکند، تشدید میشود.
بااینحال، با نگاهی به آینده، درنهایت اکثر اجزای یک FC SAN به پایان عمر مفید خود نزدیک میشوند و نیاز به تعویض دارند. در بسیاری از موارد، یک شبکه اترنت سریع و مدرن در حال حاضر وجود دارد و سرورها از قبل دارای رابطهای اترنت هستند، احتمالاً حتی قبلاً به CNA مجهز شدهاند.
بنابراین انتخاب FCoE یا iSCSI ممکن است انتخاب مناسبی باشد. اگر خرید تجهیزات ذخیرهسازی که قادر به پشتیبانی از پروتکلها یا سوئیچهای «هیبریدی» هستند که میتوانند بین شبکههای ذخیرهسازی FC و شبکههای اترنت پل شوند، امکانپذیر باشد، این دیدگاه میتواند به واقعیت تبدیل شود. استفاده از iSCSI برای محیطهای آزمایشگاهی کمهزینه یک مورد استفاده مناسب و بسیار محبوب است.
مفهومی به نام Iron Triangle «مثلث آهنی» وجود دارد که اغلب برای تجهیزات محاسباتی به کار میرود. این اصطلاح به این معنی است که: «سریع، خوب یا ارزان – هر دو را انتخاب کنید«. در مورد تجهیزات و پروتکلهای ذخیرهسازی، ممکن است جایگزینی کلمه «خوب» با «قابلاعتماد» منطقیتر باشد، اما بهطورکلی این ایده در این بحث صدق میکند. اولویتهای شما چیست؟ «سریع و قابلاعتماد» یا روش توافقی هردو راهحلهای قابلاجرا هستند – این انتخاب شماست.
پرسوجوهای DNS بهصورت متن ساده ارسال میشوند، به این معنی که هرکسی میتواند آنها را بخواند. DNS OVER HTTPS و DNS OVER TLS، پرسشها و پاسخهای DNS را رمزگذاری میکنند تا جستجوی کاربر را ایمن و خصوصی نگه دارد. بااینحال، هر دو رویکرد مزایا و معایب خود رادارند.
چرا DNS به لایههای امنیتی بیشتری نیاز دارد؟
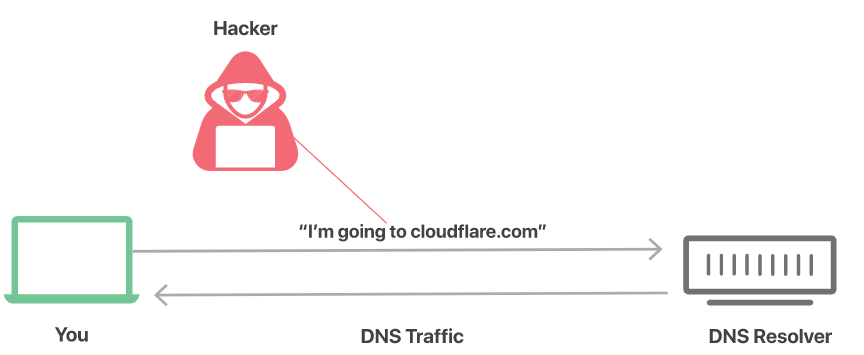
DNS دفترچه تلفن اینترنت است. DNS سرورها نامهای دامنه قابلخواندن توسط انسان را به آدرسهای IP قابلخواندن توسط ماشین ترجمه میکنند. بهطور پیشفرض، پرسشها و پاسخهای DNS بهصورت متن ساده (از طریق UDP) ارسال میشوند، به این معنی که میتوانند توسط شبکهها، ISP ها یا هر سرویسی که قادر به نظارت بر انتقال است، خوانده شوند. حتی اگر وب سایتی از HTTPS استفاده کند، پرس و جوی DNS موردنیاز برای پیمایش به آن وبسایت در معرض دید قرار میگیرد.
این فقدانِ حریم خصوصی، تأثیر زیادی بر امنیت و در برخی موارد حقوق بشر دارد. اگر کوئریهای DNS خصوصی نباشند، فیلتر اینترنت برای دولتها و ایجاد مزاحمت توسط مهاجمان برای کاربران آسانتر میشود.
یک درخواست DNS معمولی و رمزگذاری نشده را مانند یک کارتپستال در نظر بگیرید که از طریق پست ارسال میشود: هرکسی که نامه را جابجا میکند ممکن است نگاهی اجمالی به متن نوشتهشده در پشت آن بی اندازد، بنابراین عاقلانه نیست که کارتپستالی حاوی اطلاعات حساس یا خصوصی را از طریق پست ارسال کنیم.
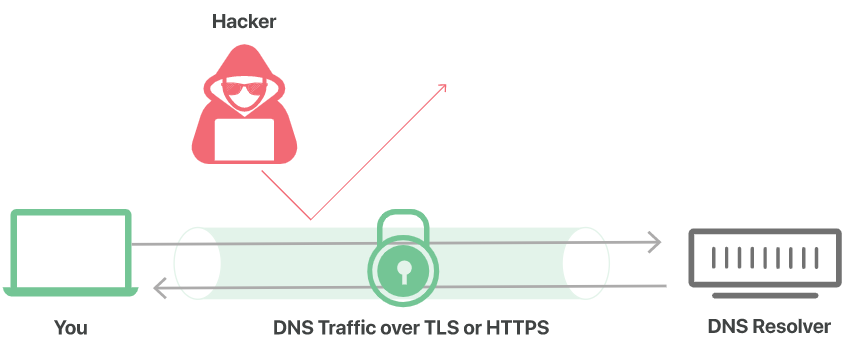
DNS OVER TLS و DNS OVER HTTPS دو استاندارد هستند که برای رمزگذاری ترافیک DNS متن ساده بهمنظور جلوگیری از امکان تفسیر دادهها توسط هکرها، شرکتهای تبلیغاتی، ISP ها و غیره ایجادشدهاند. در ادامه قیاس، هدف این استانداردها قرار دادن یک پاکت در اطراف همه کارتپستالهایی است که از طریق پست ارسال میشود، بهطوریکه هرکسی میتواند یک کارتپستال بفرستد بدون اینکه نگران باشد زیر نظر قرار میگیرد.
DNS OVER TLS چیست؟
DNS OVER TLS یا DoT استانداردی برای رمزگذاری پرسوجوهای DNS برای ایمن و خصوصی نگهداشتن آنها است. DoT از همان پروتکل امنیتی، TLS، استفاده میکند که وبسایتهای HTTPS از آن برای رمزگذاری و احراز هویت ارتباطات استفاده میکنند. (TLS همچنین بهعنوان “SSL” شناخته میشود.) DoT رمزگذاری TLS را در بالای پروتکل دیتا گرام کاربر (UDP) اضافه میکند که برای پرسوجوهای DNS استفاده میشود. علاوه بر این، تضمین میکند که درخواستها و پاسخهای DNS از طریق حملات on-path دستکاری یا جعل نمیشوند.
DNS OVER HTTPS چیست؟
DNS OVER HTTPS یا DoH جایگزینی برای DoT است. با DoH، پرسشها و پاسخهای DNS رمزگذاری میشوند، اما از طریق پروتکلهای HTTP یا HTTP/2، نه مستقیماً از طریق UDP، ارسال میشوند؛ مانند DoT، DoH تضمین میکند که مهاجمان نمیتوانند ترافیک DNS را جعل یا تغییر دهند. ترافیک DoH شبیه سایر ترافیکهای HTTPS بهعنوانمثال تعاملات عادی کاربر محور با وبسایتها و برنامههای وب – از دیدگاه مدیر شبکه است.
در فوریه 2020، مرورگر موزیلا فایرفاکس شروع به فعال کردن DoH برای کاربران ایالاتمتحده کرد. پرسوجوهای DNS از مرورگر فایرفاکس توسط DoH رمزگذاری میشوند و به Cloud flare یا NextDNS میروند. چندین مرورگر دیگر نیز از DoH پشتیبانی میکنند، اگرچه بهطور پیشفرض روشن نیست.
آیا HTTPS از TLS نیز برای رمزگذاری استفاده میکند؟ DNS over TLS و DNS over HTTPS چگونه متفاوت هستند؟
هر استاندارد بهطور جداگانه توسعهیافته است و مستندات RFC* خود را دارد، اما مهمترین تفاوت بین DoT و DoH در نوع پورتی است که استفاده میکنند. DoT فقط از پورت 853 استفاده میکند، درحالیکه DoH از پورت 443 استفاده میکند که همان پورتی است که سایر ترافیکهای HTTPS نیز از آن استفاده میکنند.
ازآنجاییکه DoT یک پورت اختصاصی دارد، هرکسی که قابلیت دید شبکه را دارد میتواند ترافیک DoT را در حال رفتوآمد ببیند، حتی اگر خود درخواستها و پاسخها رمزگذاری شده باشند. در مقابل، با DoH، پرسشها و پاسخهای DNS در سایر ترافیکهای HTTPS پنهان میشوند، زیرا همه از یک پورت میآیند و میروند.
*RFC مخفف «درخواست برای نظرات» است و RFC تلاش جمعی توسط توسعهدهندگان و کارشناسان شبکه برای استانداردسازی یک فناوری یا پروتکل اینترنت است.
پورت چیست؟
در شبکه، یک پورت یک مکان مجازی بر روی یک ماشین است که برای اتصالات سایر ماشینها باز است. هر کامپیوتر شبکهای دارای تعدادی استاندارد پورت است و هر پورت برای انواع خاصی از ارتباطات رزرو شده است.
محل بارگیری کشتیها در یک بندر را در نظر بگیرید: هر بندر کشتیرانی شمارهگذاری شده است و انواع مختلفی از کشتیها قرار است برای تخلیه بار یا مسافران به بنادر کشتیرانی خاصی بروند. شبکهسازی نیز به همین صورت است: انواع خاصی از ارتباطات قرار است به پورتهای شبکه خاصی بروند. تفاوت این است که پورتهای شبکه مجازی هستند. آنها مکانهایی برای اتصالات دیجیتال هستند تا اتصالات فیزیکی.
DoT یا DoH؟
پیرامون این موضوع اختلافنظر زیادی وجود دارد. ازنقطهنظر امنیت شبکه، DoT مسلماً گزینه مناسبتری است. DoT به مدیران شبکه این امکان را میدهد که پرسوجوهای DNS را نظارت و مسدود کنند که برای شناسایی و توقف ترافیک مخرب مهم است. در همین حال، درخواستهای DoH در ترافیک معمولی HTTPS پنهان هستند، به این معنی که نمیتوان آنها را بهراحتی بدون مسدود کردن سایر ترافیکهای HTTPS مسدود کرد.
بااینحال، از منظر حفظ حریم خصوصی، DoH مسلماً ارجح است. با DoH، پرسوجوهای DNS در جریان بزرگتر ترافیک HTTPS پنهان میشوند. DoH به مدیران شبکه دید کمتری میدهد اما حریم خصوصی بیشتری را برای کاربران فراهم میکند.
تفاوت DNS با TLS/HTTPS و DNSSEC
DNSSEC مجموعهای از پسوندهای امنیتی برای تأیید هویت سرورهای ریشه DNS و سرورهای نام معتبر در ارتباطات با سرورهای DNS است. DNSSEC برای جلوگیری از DNS Cache Poisoning، در میان سایر حملات، طراحیشده است. DNSSEC ارتباطات را رمزگذاری نمیکند. از سوی دیگر، DNS over TLS or HTTPS یا HTTPS، پرسوجوهای DNS را رمزگذاری میکند. 1.1.1.1 از DNSSEC نیز پشتیبانی میکند.
https://faradsys.com/wp-content/uploads/2022/09/DNS-over-TLSدر-مقابل-DNS-OVER-HTTPS،-DNS.jpg4751024فاطمه هاشمیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngفاطمه هاشمی2022-09-11 15:30:502022-09-18 16:09:41تفاوت DNS با DNS OVER TLS (DOT) و (DOH)DNS OVER HTTPS
3 نوع سرور DNS: DNS Resolver، DNS Root Server و Authoritative Name Server
10نوع رکورد DNS رایج: ازجمله A، AAAA، CNAME، MX و NS
DNS چگونه کار میکند
DNS یک سیستم جهانی برای تبدیل آدرسهای IP به نامهای domain مشخص است. هنگامیکه یک کاربر سعی میکند به یک آدرس وب مانند “example.com” دسترسی پیدا کند، مرورگر وب یک Query DNSرا در برابر یک سرور DNS اجرا میکند و نام میزبان را ارائه میدهد. سرور DNS نام میزبان را میگیرد و آن را به یک آدرس IP عددی تبدیل میکند که مرورگر وب میتواند به آن متصل شود.
مؤلفهای به نام DNS Resolver مسئول بررسی موجودی نام میزبان در حافظه نهان محلی می باشد و در صورتی که این نام موجود نباشد با یک سری از سرورهای نام DNS ارتباط برقرار می کند تا درنهایت آی پی سرویسی را که کاربر میخواهد به آن دسترسی پیدا کند، دریافت کند و آن را به مرورگر یا برنامه برگرداند. این فرآیند معمولاً کمتر از یک ثانیه طول میکشد.
انواع DNS : سه نوع Query DNS
سه نوع Query در سیستم DNS وجود دارد:
Query بازگشتی
در یک Query بازگشتی، یک سرویسگیرنده DNS یک نام میزبان را ارائه میدهد و » DNS Resolver باید» پاسخی را ارائه دهد – در صورت یافت نشدن، با یک رکورد منبع مرتبط یا یک پیام خطا پاسخ میدهد. Resolver یک فرآیند جستجوی بازگشتی را از DNS Root Serverشروع میکند تا زمانی که سرور نام معتبر را پیدا کند.
Query تکراری
در یک Query تکراری، یک سرویسگیرنده DNS یک نام میزبان را ارائه میدهد و DNS Resolver مناسب ترین پاسخی را که میتواند بازمیگرداند. اگر DNS Resolver رکوردهای DNS مربوطه را در حافظه پنهان خود داشته باشد، آنها را برمیگرداند. در غیر این صورت، کاربر DNS را به DNS Root Server یا سرور نام معتبر دیگری که نزدیکترین منطقه DNS موردنیاز است ارجاع میدهد .سپس کاربرDNS باید Query را مستقیماً در برابر سرور DNS که به آن ارجاع دادهشده است، تکرار کند.
Query غیر بازگشتی
Query غیر بازگشتی Query است که DNS Resolver از قبل پاسخ آن را میداند یا فوراً یک رکورد DNS را برمیگرداند زیرا قبلاً آن را در حافظه پنهان محلی ذخیره میکند، یا از یک سرور نام DNS که برای رکورد معتبر است سؤال میکند، به این معنی که قطعاً IP صحیح را برای آن نام میزبان دارد. در هر دو مورد، نیازی به دورهای اضافی Query وجود ندارد (مانند Queryهای بازگشتی یا تکراری) .در عوض، یک پاسخ بلافاصله به کاربر بازگردانده میشود.
انواع DNS: سه نوع سرور DNS
موارد زیر رایجترین انواع سرور DNS هستند که برای resolve نامهای میزبان در آدرسهای IP استفاده میشوند.
DNS Resolver
یک DNS Resolver، برای دریافت DNS queries که شامل یک نام میزبان مشخص مانند «www.example.com» است، طراحیشده است و مسئول ردیابی آدرس IP آن نام میزبان است.
DNS Root Server
DNS Root Server اولین گام در حرکت از نام میزبان به آدرس IP است DNS Root Server .دامنه (TLD) را از درخواست کاربر استخراج میکند – برای مثال www.example.com -جزئیاتی را برای سرور نام TLD.com ارائه میدهد. در نتیجه، آن سرور جزئیاتی را برای دامنههای دارای منطقه DNS.com ازجمله “example.com” ارائه میدهد.
13 Root Serverدر سراسر جهان وجود دارد که با حروف A تا M نشان دادهشده است و توسط سازمانهایی مانند کنسرسیوم سیستمهای اینترنت، Verisign، ICANN، دانشگاه مریلند و آزمایشگاه تحقیقات ارتش ایالاتمتحده اداره میشود.
Authoritative DNS Server
سرورهای سطح بالاتر در رده بندی DNS تعریف میکنند که کدام سرورDNS، Authoritative Name Server برای یک نام میزبان خاص است، به این معنی که اطلاعات بهروز را برای آن نام میزبان نگهداری میکند.
Authoritative Name Server آخرین توقف در Query سرور نام است – نام میزبان را میگیرد و آدرس IP صحیح را به DNS Resolverبرمیگرداند (اگر دامنه را پیدا نکرد، پیام NXDOMAIN را برمیگرداند).
انواع 10 : DNS نوع رکورد برتر DNS
سرورهای DNS یک رکورد DNS برای ارائه اطلاعات مهم در مورد یک دامنه یا نام میزبان، بهویژه آدرس IP فعلی آن ایجاد میکنند. رایجترین انواع رکورد DNS عبارتاند از:
رکورد نگاشت آدرس (A Record) – که بهعنوان رکورد میزبان DNS نیز شناخته میشود، نام میزبان و آدرس IPv4 مربوط به آن را ذخیره میکند.
IP نسخه 6 رکورد آدرس (AAAA Record) – نام میزبان و آدرس IPv6 مربوطه آن را ذخیره میکند.
رکورد نام (CNAME Record) Canonical میتواند برای نام مستعار میزبان نام میزبان دیگر استفاده شود. هنگامیکه یک سرویسگیرنده DNS رکوردی را درخواست میکند که حاوی یک CNAME است که به نام میزبان دیگری اشاره میکند، فرآیند DNS resolution بانام میزبان جدید تکرار میشود.
رکورد مبدل ایمیل (MX Record) یک سرور ایمیل SMTP را برای دامنه مشخص میکند که برای مسیریابی ایمیلهای خروجی به سرور ایمیل استفاده میشود.
رکوردهای سرور نام (NS Record) مشخص میکند که یک منطقهDNS، مانند “example.com” به یک سرور نام معتبر خاص واگذار میشود و آدرس سرور نام را ارائه میدهد.
سوابق اشارهگر جستجوی معکوس (PTR Record) – به یک DNS Resolverاجازه میدهد یک آدرس IP ارائه کند و یک نام میزبان دریافت کند (جستجوی معکوس DNS).
رکورد گواهی(CERT Record) گواهیهای رمزگذاری – PKIX، SPKI، PGP و غیره را ذخیره میکند.
محل سرویس (SRV Record) – یک رکورد موقعیت مکانی سرویس، مانند MX اما برای سایر پروتکلهای ارتباطی.
Text Record (TXT Record) معمولاً دادههای خوانای ماشین مانند رمزگذاری فرصتطلبانه، چارچوب خطمشی فرستنده، DKIM، DMARC و غیره را حمل میکند.
Start of Authority (SOA Record) این رکورد در ابتدای یک فایل منطقه DNS ظاهر میشود و سرور نام معتبر برای منطقه DNS فعلی، جزئیات تماس برای سرپرست دامنه، شمارهسریال دامنه و اطلاعات مربوط به تعداد دفعات اطلاعات DNS را که برای این منطقه باید تجدید شود نشان میدهد.
خدمات DNS
اکنونکه ما انواع اصلی زیرساختهای DNS سنتی را پوشش دادیم، باید بدانید که DNS میتواند چیزی بیش از «سیستم لولهکشی» اینترنت باشد. DNS خدمات فوق العاده ای ارائه می دهد، ازجمله:
مدیریت ترافیک اینترنت :کاهش ازدحام شبکه و اطمینان از جریان ترافیک به منبع مناسب به شیوهای بهینه
این قابلیتها توسط سرورهای DNS نسل بعدی که قادر به مسیریابی و فیلتر کردن ترافیک هوشمند هستند امکانپذیر شده است .
https://faradsys.com/wp-content/uploads/2022/09/low.jpg431768فاطمه هاشمیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngفاطمه هاشمی2022-09-04 15:30:292022-09-04 15:45:27 DNS: انواع رکوردهای DNS، سرورهای DNS و Query های DNS
شبکه کامپیوتری(Authentication, Authorization, Accounting) AAA
Admin میتواند از طریق یک کنسول به یک Router یا یک دستگاه دسترسی داشته باشد اما شرایط نامطلوب زمانی بوجود می آید که امکان ارتباط با دستگاه از نزدیک میسر نیست و بنابراین، باید از راه دور به آن دستگاه دسترسی داشته باشد.
اما ازآنجاییکه دسترسی از راه دور با استفاده از یک آدرس IP امکانپذیر خواهد بود، ممکن است یک کاربر غیرمجاز بتواند با استفاده از همان آدرس IP به سیستم دسترسی پیدا کند. بنابراین برای اقدامات امنیتی، باید Authentication انجام دهیم. همچنین بستههای مبادله شده بین دستگاه باید رمزگذاری شوند تا هر شخص دیگری نتواند آن اطلاعات حساس را به دست آورد. بنابراین، چارچوبی به نام AAA برای تأمین آن سطح امنیتی ویژه استفاده میشود.
AAA: AAA یک چارچوب مبتنی بر استاندارد است که برای کنترل افرادی که مجاز به استفاده از منابع شبکه (از طریق Authentication) هستند، آنچه مجاز به انجام آن هستند (از طریق Authorization) و دسترسی به اقدامات انجامشده در حین دسترسی به شبکه (از طریق Accounting)، استفاده می شود.
احراز هویت (Authentication)
فرآیندی که توسط آن میتوان تشخیص داد که کاربری که میخواهد به منابع شبکه دسترسی پیدا کند، با درخواست برخی از اطلاعات هویتی مانند نام کاربری و رمز عبور، معتبر است یا خیر. روشهای رایج عبارتاند از قرار دادن Authenticationدر پورت کنسول، پورت AUX یا خطوط vty.
اگر شخصی بخواهد به شبکه دسترسی پیدا کند، بهعنوان سرپرست شبکه، میتوانیم نحوه Authenticationکاربر را کنترل کنیم. برخی از این روشها شامل استفاده از پایگاه داده محلی (Router) یا ارسال درخواستهای Authenticationبه یک سرور خارجی مانند سرور ACS است. برای تعیین روشی که برای Authenticationاستفاده میشود، از method list Authenticationپیشفرض یا سفارشی استفاده میشود.
2. مجوز (Authorization)
قابلیتهایی را برای اعمال سیاستها در منابع شبکه پسازاینکه کاربر از طریق Authenticationبه منابع شبکه دسترسی پیدا کرد، فراهم میکند. پس از موفقیتآمیز بودن احراز هویت، میتوان از Authorization برای تعیین اینکه کاربر مجاز به دسترسی به چه منابعی است و عملیاتی که میتواند انجام شود استفاده کرد.
بهعنوانمثال، اگر یک مهندس شبکه تازه کار(که نباید به همه منابع دسترسی داشته باشد) بخواهد به دستگاه دسترسی داشته باشد، Admin میتواند نمایهای ایجاد کند که اجازه دهد دستورات خاص فقط توسط کاربر اجرا شوند (فرمانهایی که درروش فهرست مجاز هستند. Admin میتواند از method list مجاز استفاده کند تا مشخص کند کاربر چگونه برای منابع شبکه مجاز است، یعنی از طریق یک پایگاه داده محلی یا سرور .ACS
حسابداری(Accounting)
ابزاری برای کنترل و ثبت رویدادهای انجامشده توسط کاربر در حین دسترسی به منابع شبکه را فراهم میکند.حتی بر مدتزمانی که کاربر به شبکه دسترسی دارد نظارت میکند. Admin میتواند یک method list حسابداری ایجاد کند تا مشخص کند که چه چیزی باید حسابداری شود و سوابق حسابداری برای چه کسی ارسال شود.
پیادهسازی AAA:AAA را میتوان با استفاده از پایگاه داده محلی دستگاه یا با استفاده از یک سرور ACS خارجی پیادهسازی کرد.
پایگاه داده محلی –اگر میخواهیم از پیکربندی در حال اجرای محلی Router یا سوئیچ برای پیادهسازی AAA استفاده کنیم، ابتدا باید کاربرانی را برای Authenticationایجاد کنیم و سطوح امتیاز را برای Authorization به کاربران ارائه دهیم.
سرور – ACS این، روش رایج مورداستفاده است. یک سرور ACS خارجی )میتواند دستگاه ACS یا نرمافزار نصبشده روی Vmware باشد( برای AAA استفاده میشود که روی آن پیکربندی روی Router و ACS موردنیاز است. این پیکربندی شامل ایجاد یک کاربر، method list سفارشی جداگانه برای احراز هویت، Authorization و حسابداری است.
کلاینت یا سرور دسترسی شبکه (NAS) درخواستهای Authenticationرا به سرور ACS ارسال میکند و سرور تصمیم میگیرد که به کاربر اجازه دهد طبق اعتبار ارائهشده توسط کاربر به منبع شبکه دسترسی داشته باشد یا نه.
توجه – اگر سرور ACS موفق به Authenticationنشد، Admin باید استفاده از پایگاه داده محلی دستگاه را بهعنوان پشتیبان، در method list، برای پیادهسازی AAA ذکر کند.
https://faradsys.com/wp-content/uploads/2022/08/images-1.jpg306658فاطمه هاشمیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngفاطمه هاشمی2022-08-21 15:30:132022-08-21 15:34:24آشنایی با AAA (Authentication, Authorization and Accounting)
آخرین لیست OWASP پیرامون تهدیدهای رایج برای شرکتها در سال 2022 و چگونگی محافظت در برابر آنهاست.
OWASP بهتازگی لیست اصلاحشده خود را از ده مورد آسیبپذیری مهم برای مشاغل در سالهای 2021-2022، پنج سال پس از آخرین اطلاعیه خود منتشر کرده است.
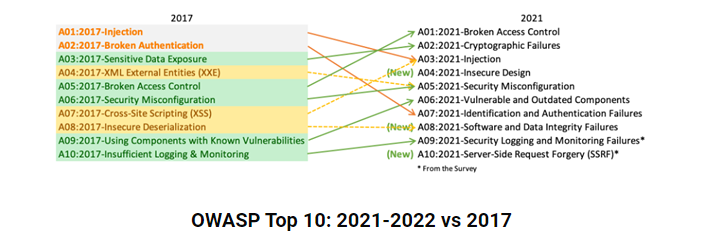
OWASP Top 10 مدل 2021-2022 در مقایسه با مدل 2017
Open Web Application Security Project (OWASP) یک سازمان غیردولتی است که هدف آن بهبود امنیت نرمافزار است. OWASP یک فروشگاه چندمنظوره برای افراد، شرکتها، سازمانهای دولتی و سایر سازمانهای جهانی است که به دنبال عیبیابی و دانش واقعی در مورد امنیت application هستند. OWASP خدمات یا محصولات تجاری را تبلیغ نمیکند، اما مجموعهای از دوره های خود را در مورد امنیت برنامهها و حوزههای مرتبط ارائه میدهد.
علاوه بر این، مفهوم “open community” را مطرح میکند، به این معنی که هرکسی آزاد است در مکالمات آنلاین OWASP، طرحها و سایر فعالیتها شرکت کند. OWASP تضمین میکند که تمام منابع خود، ازجمله ابزارهای آنلاین، ویدیوها، انجمنها و رویدادها، از طریق وبسایت خود در دسترس عموم قرار گیرد. با افزایش جرائم سایبری، حملات (DDoS)، کنترل دسترسی معیوب و فاش شدن اطلاعات به دفعات اتفاق میافتد. بنیاد OWASP، OWASP Top 10را برای جلوگیری از این نگرانیهای امنیتی ایجاد کرد. OWASP Top 10 یک رتبهبندی از ده خطر جدی امنیتی برای برنامههای آنلاین موجود است که بر اساس اولویت آورده شده است. آخرین لیست OWASP Top 10در سال 2017 منتشر شد که اخیراً در سهماهه چهارم سال 2021 بهروزرسانی شده است.
در اینجا برخی از تغییرات مهم قابل مشاهده است:
A03: SQL Injections 2021 گستردهتر میشوند
اولین اصلاحات در ارتباط با SQL Injections است. حملات SQL Injections زمانی اتفاق میافتد که یک هکر سعی میکند دادهها را به یک برنامه وب ارسال کند، بهطوریکه برنامه وب یک عمل ناخواسته را انجام دهد. اینها ممکن است شامل اشکالات SQL Injections، سیستمعامل و پروتکل (LDAP) باشد. ازآنجاییکه این نقص نیز injectable است، بهروزرسانی فعلی OWASP Top 10 حملات(XSS) A07:2017 را تشدید میکند.
A05: پیکربندی اشتباه امنیتی 2021 در اولویت قرار دارد
با توجه به افزایش تعداد گزینههای پیکربندی، این دسته در OWASP Top 10 ارتقا یافته است. حمله XXE یک برنامه client-sideرا هدف قرار میدهد که ورودی XML را پردازش میکند. یک XML-External-Entities-Attack زمانی اتفاق میافتد که ارجاعات ورودی XML ناامن، به موجودیتهای خارجی تفسیر و پردازش شوند. بااینحال، این حمله تنها با یک تجزیهکننده XML معیوب یا پیکربندی نامناسب موفقیتآمیز است؛ بنابراین، A04:2017-XML External Entities (XXE) در A05:2021-Security misconfiguration بهعنوان یک نوع خاص از پیکربندی نادرست ادغامشده است.
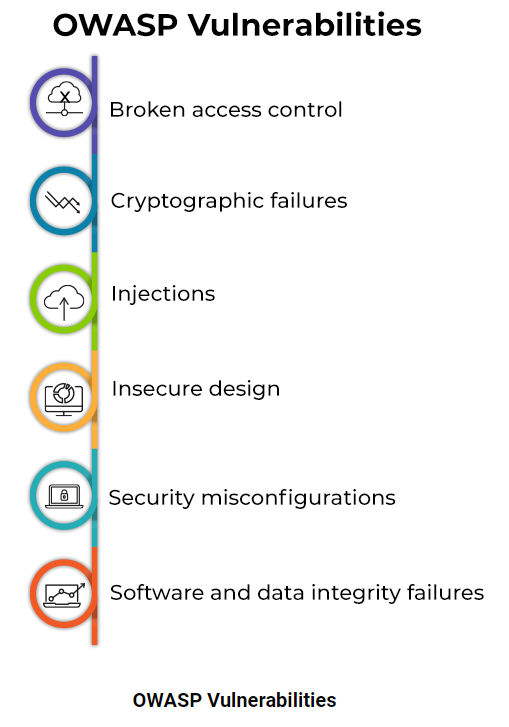
10 آسیبپذیری برتر OWASP برای سال 2022 چیست؟
سه دستهبندی جدید در OWASP Top 10 سال 2021 با تغییرات و ادغام دامنه و نامگذاری اضافه شده است. برای شروع و محافظت در برابر این تهدیدها، در اینجا مهمترین آسیبپذیریهای امنیتی که باید در سال 2022 مراقب آنها بود، آورده شده است:
کنترل دسترسی خرابBroken access control
کنترل دسترسی استراتژیهایی را برای جلوگیری از عملکرد کاربران فراتر از محدوده مشخصشده خود پیادهسازی میکند. به دلیل آسیبپذیریهای دسترسی، کاربران احراز هویت نشده ممکن است به دادهها و فرآیندهای طبقهبندیشده و تنظیمات امتیاز کاربر دسترسی داشته باشند.
دستکاری metadata، ازجمله دستکاری یا اجرای مجدد یک نشانه کنترل دسترسی JSON (JWT)، یا تغییر cookies یا فیلدهای مخفی برای افزایش امتیازات یا سوء استفاده از باطل شدن JWT، نمونهای از آسیبپذیری کنترل دسترسی است. مثال دوم نقض اصل denial بهطور پیشفرض است. دسترسی باید فقط به نقشها، قابلیتها یا کاربران خاصی داده شود، اما برای همه قابلدسترسی است. چنین خطاهایی ممکن است دسترسی Attackers به همه جا را آسان کنند.
بااینحال، ممکن است با استفاده از رویکردهای کدگذاری ایمن و انجام اقدامات احتیاطی مانند غیرفعال کردن حسابهای admin و محدودیتها و نصب احراز هویت چندعاملی، از مکانیسمهای امنیتی دسترسی ناکافی و مسائل مربوط به مدیریت هویت یا رمز عبور جلوگیری کنید.
تکنیکهای پیشگیری تکمیلی عبارتاند از:
مکانیسمهای کنترل دسترسی را فقط یکبار اجرا کنید و برای کاهش اشتراکگذاری منابع متقاطع (CORS) از آنها برای مدتزمان برنامه مجددا استفاده کنید.
مدلهای Domain باید موانع محدود تجاری یک application متفاوت را اعمال کنند.
دسترسی به رابطهای برنامهنویسی برنامه (API) و کنترلکنندهها را محدود کنید تا اثرات ابزارهای حمله خودکار را کاهش دهید.
هر گونه اشکال در کنترل دسترسی را یادداشت کرده و در صورت لزوم به مدیران اطلاع دهید.
بهجای ارائه دسترسی به کاربر برای ایجاد، مشاهده، اصلاح یا پاک کردن هرگونه اطلاعات، کنترلهای دسترسی model باید از مالکیت رکورد تبعیت کنند.
مشکلات رمزنگاری(Cryptographic Failures)
مشکلات رمزنگاری که قبلاً بهعنوان قرار گیری در معرض دادههای حساس شناخته میشد، به جایگاه دوم رسید. این بیشتر یک علامت است تا اینکه علت اصلی باشد. در اینجا تأکید بر خطاهای رمزنگاری یا عدم وجود آنها است که اغلب دادههای حساس را در معرض دید قرار میدهد. موارد زیر نمونههای متداولی از قرار گرفتن در معرض اطلاعات حساس هستند:
توکنهای Session
شناسههای ورود و رمز عبور
معاملات آنلاین
اطلاعات شخصی (شبکه سرویس سوئیچ شده یا SSN، health records و غیره)
بهعنوانمثال، یک application ممکن است بهطور ایمن دادههای کارت اعتباری را با رمزگذاری خودکار پایگاه داده انجام دهد. متأسفانه، هنگامیکه به این اطلاعات دسترسی پیدا میشود، رمزگذاری بلافاصله انجام نمی گیرد و یک خطای Injection SQL را قادر میسازد تا اطلاعات کارت اعتباری را در قالب یک متن مشخص استخراج کند که ممکن است یک فرد خاطی از آن سوءاستفاده کند. با استفاده از تکنیکهای پیشگیری زیر میتوان از این مشکلات جلوگیری کرد:
شما باید از الگوریتمهای hashing قوی، salted و تطبیقی با ضریب تأخیر برای ذخیره رمزهای عبور از قبیل scrypt، Argon2، PBKDF2 یا bcrypt استفاده کنید.
هنگام انتقال دادههای حساس باید از پروتکلهای قدیمیتر مانند پروتکل انتقال فایل (FTP) و پروتکل انتقالنامه ساده (SMTP) اجتناب شود.
بهجای استفاده صرف از رمزگذاری، توصیه میشود رمزگذاری تأییدشده را پیادهسازی کنید.
کلیدهای تصادفی رمزنگاری باید بهصورت آرایه بایت تولید و ذخیره شوند. اگر از رمزهای عبور استفاده میشود، باید با استفاده از الگوریتمی برای ایجاد کلید مبتنی بر رمز عبور، به چیزی شبیه به یک کلید تبدیل شود.
SQL Injection
SQL Injection (یا Injection) یک حمله پایگاه داده علیه وبسایتی است که از زبان (SQL) برای به دست آوردن اطلاعات یا انجام فعالیتهایی استفاده میکند که معمولاً به یک حساب کاربری تأییدشده نیاز دارند. تفسیر این کدها برای برنامه از روی کد خود دشوار است و به مهاجمان این امکان را میدهد که حملات SQL Injection را انجام دهند تا به مناطق محافظتشده دسترسی داشته باشند و دادههای حساس را بهعنوان کاربران قابلاعتماد پنهان کنند. SQL Injection شامل SQL Injection، SQL Injection فرمان، SQL Injection CRLF و SQL Injection LDAP و غیره است.
با حداکثر بروز تخمینی 19 درصد، میانگین میزان بروز 3 درصد و 274000 مورد، 94 درصد از برنامهها برای SQL Injection غربالگری شدند. درنتیجه، Injection به رتبه سوم در لیست اصلاحشده سقوط کرد.
برخی از تکنیکهای پیشگیری عبارتاند از:
یک جایگزین ترجیحی استفاده از یک API است که بهطور کامل از مفسر اجتناب میکند، یک API پارامتری ارائه میدهد، یا به ابزارهای نگاشت شی – رابطه (ORM) منتقل میشود.
استفاده از ورودی اعتبارسنجی مثبت سمت سرور توصیه میشود. برنامههای کاربردی متعدد، ازجمله فیلدهای متنی و API برای برنامههای تلفن همراه، به کاراکترهای ویژهای نیاز دارند.
استفاده از LIMIT و سایر محدودیتهای SQL در داخل پرسوجوها راهی عالی برای جلوگیری از قرار گرفتن در معرض دادههای عظیم در مورد SQL Injection است.
بیشتر بخوانید: فایروال چیست؟ تعریف، مؤلفههای کلیدی و بهترین روشها
طراحی ناامن
اینیک مقوله کاملاً جدید برای سال 2021 است که بر روی اشکالات طراحی و معماری تمرکز دارد و نیاز به استفاده بیشتر از مدلسازی تهدید، توصیههای ایمنی طراحی و معماریهای مرجع دارد. طراحی ناایمن مقوله وسیعی است که شامل مشکلات گوناگونی است، مانند «نقص یا ناکافی بودن طراحی کنترل.» این بدان معنا نیست که طراحی ناامن ریشه تمام 10 دسته خطر اصلی دیگر است.
طراحی ناایمن با اجرای ناایمن یکسان نیست. نقصهای پیادهسازی میتواند منجر به آسیبپذیریها شود، حتی زمانی که طراحی امن باشد. از سوی دیگر، یک طراحی معیوب را نمیتوان با اجرای بیعیب و نقص جبران کرد زیرا تدابیر امنیتی لازم برای دفاع در برابر تهدیدات خاص وجود ندارد.
میتوان با استفاده از تکنیکهای پیشگیری زیر از این تهدیدات جلوگیری کرد:
با کمک متخصصان AppSec یک چرخه حیات توسعه ایمن را برای ارزیابی و ایجاد تدابیر امنیتی و حریم خصوصی تنظیم و استفاده کنید.
راهاندازی و استفاده از Lifecycle توسعه ایمن با کمک متخصصان AppSec برای ارزیابی و ایجاد تدابیر امنیتی و حفظ حریم خصوصی توصیه میشود.
اصطلاحات امنیتی و کنترلها را در Story های کاربر قرار دهید.
Tenant segregation بر اساس طراحی در تمام سطوح نیز بهعنوان یک رویکرد پیشگیرانه عملی دیده میشود.
تنظیمات اشتباه امنیتی
مسائل اجرای امنیت عمومی، مانند کنترلهای دسترسی نادرست پیکربندیشده، با فراهم کردن دسترسی سریع و آسان Attackers به دادههای حیاتی و Site Regions، خطرات قابلتوجهی ایجاد میکند.
OWASP با نرخ متوسط بروز 4% و بیش از 208000 رخداد[1] (CWE) در این دسته، 90% برنامهها را برای پیکربندی نادرست بررسی کرد. «پیکربندی CWE-16 و محدودیت نامناسب CWE-611 مرجع خارجی XML، دو CWE قابلتوجه هستند». برای جلوگیری از پیچیدگیهای پیکربندی، باید از تکنیکهای نصب ایمن استفاده کرد که عبارتاند از:
یک فرآیند تقویت سیستماتیک امکان استقرار سریع و آسان یک محیط امن را فراهم میکند. پیکربندی محیطهای توسعه، کنترل کیفیت و عملیاتی باید مشابه و دارای امتیازات کاربر متمایز باشد.
برای خودکارسازی فرآیندها در جهت ایجاد یک محیط امن جدید، صرفهجویی در زمان و تلاش لازم، ایده آل است. ویژگیها و فریمورک های استفادهنشده باید حذف شوند یا نصب نشوند. یک پلتفرم اصلی بدون ویژگیها، مؤلفهها، مستندات یا نمایشهای غیرضروری، احتمال آسیبپذیریهای پیکربندی را کاهش میدهد.
اجزای آسیبپذیر و قدیمی
اکثر برنامههای آنلاین با کمک چارچوبهای شخص ثالث ایجاد میشوند. کدهای برنامه ناشناخته ممکن است منجر به نتایج نامطلوب و موقعیتهای ناخواسته مانند Accent Control Violations، SQL Injection و غیره شود.
اگر برنامه ناامن، پشتیبانی نشده یا قدیمی باشد، ممکن است خطرات مربوط به آسیبپذیری وجود داشته باشد. این بسته شامل Application / وب سرور، سیستمعامل، Applications، سیستم مدیریت پایگاه داده (DBMS)، API ها، عناصر دیگر، کتابخانهها و محیطهای زمان اجرا میباشد.
رویکردهای خودکار برای کمک به Attackers دریافتن ماشینهایی که بهدرستی پیکربندی نشده یا وصله نشدهاند، در دسترس هستند. برای مثال، موتور جستجوی IoT Shodan ممکن است به کاربران در کشف دستگاههایی که در معرض تهدید Heartbleed هستند که در آوریل 2014 رفع شد، کمک کند. برخی از تکنیکهای پیشگیری عبارتاند از:
بهتر است قطعات را از منابع معتبر از طریق کانالهای امن خریداری کنید.
مراقب ماژولها و عناصری باشید که کاربردی نیستند یا بهروزرسانیهای امنیتی را برای نسخههای قدیمیتر ارائه نمیکنند. اگر نمیتوان Patching را انجام داد، برای مشاهده، شناسایی یا محافظت در برابر آسیبپذیری مشاهدهشده، Patching مجازی ایجاد کنید.
هرگونه الزامات، قابلیتها، عناصر، پوشهها یا اسناد اضافی را حذف کنید.
مشکلات شناسایی و احراز هویت
این دسته که قبلاً بهعنوان احراز هویت ناقص شناخته میشد، از رتبه دوم سقوط کرد و اکنون حاوی CWE های مرتبط با مشکلات شناسایی است. هنگامیکه یک Attacker اطلاعات کاربر، بازیابی رمز عبور، جلسات ID و سایر اعتبارنامههای ورود را به دست میآورد، مشکلات امنیتی ایجاد میکند. همانطور که از نام آن پیداست، مشکلات احراز هویت و شناسایی شامل هکرهایی است که از چنین آسیبپذیریهایی برای استفاده از احراز هویت نادرست سوءاستفاده میکنند.
اگر برنامه اجازه حملات خودکار مانند پر کردن اعتبار – زمانی که Attacker به لیست کاربران واقعی و گذرواژهها دسترسی دارد – یا گذرواژههای از پیش تعریفشده، ضعیفتر و رایج مانند «Password1» یا «Admin/Admin» را میدهد، اینها میتواند نشانهای از نقصهای احراز هویت باشد.
برای جلوگیری از چنین نقصهایی، باید اقدامات پیشگیرانه زیر را در نظر گرفت:
احراز هویت چندعاملی باید هر جا که امکانپذیر باشد برای جلوگیری از پر کردن خودکار اعتبار، حملات brute-force و استفاده مجدد از اعتبارنامههای سرقت شده استفاده شود.
با بررسی گذرواژههای جدید یا اصلاحشده در برابر پایگاه دادهای از 10000 مورد از ضعیفترین رمز عبورها، میتوان امنیت رمز عبور را افزایش داد.
استفاده از پیامهای مشابه برای هر نتیجه، به جلوگیری از حملات شمارش حساب در بازیابی رمز عبور، ثبتنامها و مسیرهای API کمک میکند.
هیچ اعتبار پیشفرضی را نصب نکنید، بهخصوص برای کاربران اداری.
نقص نرمافزار و یکپارچگی دادهها
ازآنجاییکه اطلاعات حساستر در پایگاههای داده ذخیره میشوند و در برابر نقضهای امنیتی آسیبپذیر هستند، نگرانیهای یکپارچگی دادهها برای نرمافزار ضروری میشود.
اینیک مقوله جدید است و برفرض یکپارچگی بهروزرسانیهای نرمافزار، دادههای حیاتی و رویههای CI/CD بدون تأیید آنها، تمرکز دارد. یک مثال زمانی است که برنامهها از افزونهها، ماژولها یا مخازن از شبکههای تحویل محتوا (CDN) یا منابع غیرمجاز استفاده میکنند. یک فرآیند یکپارچهسازی/تحویل پیوسته (CI/CD) که محافظت نشده است ممکن است خطر کد مخرب، به خطر افتادن سیستم یا دسترسی غیرمجاز را افزایش دهد.
تکنیکهای پیشگیری عبارتاند از:
میتوان از معیارهایی مانند امضای دیجیتال برای تأیید اینکه دادهها یا نرمافزار از منابع مورد انتظار بدون هیچگونه دستکاری تهیهشدهاند، استفاده کرد.
یک ابزار امنیتی برای زنجیرههای تأمین نرمافزار، مانند OWASP CycloneDX یا OWASP Dependency-Check، ممکن است برای تضمین عدم وجود ایرادات طراحی در اجزا استفاده شود.
لازم است تضمین شود که گردش کار CI/CD دارای بخشبندی، کنترل دسترسی و پارامتر سازی لازم برای محافظت از یکپارچگی کد در طول عملیات راهاندازی و استقرار است.
دادههای جمعآوریشده بدون امضا یا رمزگذاری نشده نباید به مشتریان غیرقابلاعتماد ارسال شوند، مگر اینکه آزمایش یکپارچگی یا امضای دیجیتالی برای شناسایی تغییر یا تکرار دادهها وجود داشته باشد.
مشکلات logging و monitoring امنیتی
عدم ردیابی اقدامات و رویدادهای مشکوک میتواند شکافهای زمانی نظارتنشده را افزایش دهد و اجازه میدهد نقضهای امنیتی برای مدت طولانیتری بهواسطه logging مناسبتر نادیده گرفته شوند. این بخش OWASP Top 10 2021 بهمنظور کمک به شناسایی، تشدید و حلوفصل نقضهای اخیر است. تشخیص نقض امنیتی احتمالاً بدون ثبت و کنترل است.
یک شرکت هواپیمایی بزرگ اروپایی برای نشان دادن این شکست، یک رویداد گزارشی(GDPR) داشت. احتمالاً متخلفان از نقایص امنیتی app پرداخت برای به دست آوردن اطلاعات بیش از 400000 پرداختی مصرفکنندگان سوءاستفاده کردهاند. در پاسخ، متصدیان حریم خصوصی، این شرکت هواپیمایی را به دلیل دادههای نادرست، 20 میلیون پوند جریمه کردند. برای جلوگیری از چنین حملاتی، لازم است کاربران نکات زیر را در نظر بگیرند:
بررسی تمامی مشکلات authentication، سیستمهای امنیتی دسترسی و اعتبارسنجی دادههای server-side با استفاده از اطلاعات کافی کاربر برای شناسایی حسابهای مشکوک یا کلاهبردار ثبتشده که برای یک دوره مناسب ذخیره میشوند تا تحقیقات جامعی در زمان مناسب صورت گیرد.
کسب اطمینان از ایجاد log ها در فرمتهای قابلقبول توسط سیستمهای مدیریت log
بهکارگیری یک استراتژی برای اعمال بازیابی رویدادها و تلاشهای پاسخ، مانند NIST 800-61r2 یا نسخه جدیدتر.
کسب اطمینان از کدگذاری صحیح دادههای گزارش برای جلوگیری از نفوذ یا تهدیدات سایبری برای سیستمهای نظارتی
https://faradsys.com/wp-content/uploads/2022/08/OWASP-Logo.jpg500750فاطمه هاشمیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngفاطمه هاشمی2022-08-14 15:30:152022-08-20 17:22:0610 آسیبپذیری مهم OWASP در سال 2022
تا کنون سیسکو از سیستمعاملهای بسیاری رونمایی کرده است که تعداد زیادی از آنها اکنون دیگر ازردهخارج شدهاند. برخی از این سیستمعاملها حاصل ادغام شرکتهای مختلف توسط شرکت سیسکو بودند. بهعنوانمثال، در اواسط دهه 1990، سیسکو با خرید شرکتهای Grand Junction، Kalpana و Crescendo شروع به توسعه خط تولید سوئیچهای کاتالیست سیسکو کرد. این سوئیچها سیستمعاملهای متفاوتی را اجرا میکردند. محصولات سیسکو همچنین با سیستمعاملهای گوناگونی برای هابهای خود، Load Balancers، سختافزارهای امنیتی، ماژولهای پیامرسانی یکپارچه و غیره به بازار عرضه شدند. بااینحال، سیستمعامل IOS سیسکو تا مدتها عملاً سیستمعامل مورداستفاده این شرکت شناخته میشد که بر روی طیف وسیعی از روترها و سوئیچهای سیسکو کاتالیست اجرا میشد. اما نکته جالبتوجه این است که چندین سیستمعامل دیگر سیسکو به شهرت رسیدهاند و امروزه در حال استفاده گسترده هستند، بهویژه: NX-OS و IOS-XR.
این پست پیرامون تفاوتهای عمده بین سیستمعاملهای IOS، NX-OS، و IOS-XR شرکت سیسکو میباشد و همچنین اطلاعاتی در خصوص این که در چه مکانها و موقعیتهایی ممکن است با هرکدام از این سیستمعاملها مواجه شوید را در اختیار شما قرار میدهد. ابتدا، در نظر داریم به بررسی مقایسهای آنها در سطح پیشرفته بپردازیم:
سیستمعامل IOS سیسکو: این نوع از سیستمعاملها، در «شبکههای بدون محدودیت» یافت میشوند (یعنی شبکههایی که به «هرکسی، در هر مکان و با هر تجهیزات سختافزاری» اجازه میدهد به یک شبکه شرکتی متصل شود). بهعنوانمثال، یکروتر ISR2 سری 3900 سیسکو، سیستمعامل IOS را اجرا میکند.
سیستمعامل NX-OSسیسکو: این سیستمعامل در سوئیچهای Nexus واقع در مراکز داده یافت میشود. بهعنوانمثال، یک سوئیچ سیسکوی Nexus سری 7000، یک سیستمعامل NX-OS را اجرا میکند.
سیستمعامل IOS-XRسیسکو: در روترهای ارائهدهنده خدمات سیسکو یافت میشود. بهعنوانمثال، یکروتر سیسکو XR سری 12000، یک سیستمعامل IOS-XRرا اجرا میکند.
درگذشته، سه گروه سازمانی مجزا در شرکت سیسکو وجود داشتند که این سیستمعاملها را توسعه دادند. خوشبختانه، این سه گروه در حال حاضر تحت یک واحد سازمانی مشترک در سیسکو ترکیب شدهاند. این ادغام سازمانی تاکنون منجر به سازگاری بیشتر بین این سیستمعاملهای متنوع شده است. بااینحال، تفاوتهای قابلتوجهی هنوز وجود دارد. برای درک بهتر تفاوتهای اساسی، در ادامه برخی از ویژگیهای اصلی هر سیستمعامل را بیان میکنیم:
سیستمعامل IOSسیسکو
اگرچه اصطلاح “IOS” بعدها مطرح شد، قدمت این سیستمعامل به اواسط دهه 1980 بازمیگردد. سیستمعامل IOS با استفاده از زبان برنامهنویسی C توسعه یافت و دارای محدودیتهای متعددی بود که مربوط به زمان تولید آن بود. بهعنوانمثال، از چند پردازش متشابه پشتیبانی نمیکرد. در نتیجه، پیش از اینکه مجموعهای از کدهای دستوری شروع به اجرا شوند، باید یک کد دستوری تکمیل میشد. یکی دیگر از محدودیتهای مهم ساختاری، استفاده از فضای حافظه مشترک بود. پیشازاین، همه فرایندها از یک منبع حافظه استفاده میکردند و یک پردازش OSPF1 نادرست (بهعنوانمثال) میتوانست باعث ایجاد اختلال در سایر فرایندهای روتر شود.
برخی از پلتفرمهای روتر راهحلهای جایگزینی را ارائه میدادند. برای نمونه، یکروتر ماژولار 7513 سیسکو میتوانست به یک ماژول پردازشگر رابط همهکارهVIP 2 مجهز شود که کارتهای شبکه اختصاصی را قادر میساخت تا مدلهای نمونهسازی شده خود را از سیستمعامل IOS اجرا کنند که سطحی از تعادل را برای حجم ترافیک و افزونگی اطلاعات فراهم میکرد.
توجه: نسخه دیگری از سیستمعامل IOS که ممکن است نامش را شنیده باشید سیستمعاملIOS-XE است که سیستمعامل IOS را روی لینوکس اجرا میکند. بهعنوانمثال، میتوانید سیستمعامل IOS-XE سیسکو را در حال اجرا بر روی روتر ASR سری 1000 سیسکو بیابید. سیستمعامل IOS-XE سیسکو به لطف مجموعه ویژگیهای لینوکس، پشتیبانی از چند پردازش مشابه و فضاهای حافظه اختصاصی را ارائه میدهد. بااینحال، بهغیراز زیربنای لینوکس، IOS-XE در اصل همان سیستمعامل IOS قبلی است؛ بنابراین، در این مقاله رویکرد مشخصی برای آن ارائه داده نشده است.
سیستمعامل NX-OS سیسکو
این سیستمعامل که در ابتدا SAN نام داشت (مخفف Storage Area Network بود)، امکانات ساختاری گستردهتری را نسبت به نسخه قدیمی سیستمعامل IOS سیسکو ارائه میدهد. اگرچه سیستمعاملNX-OS در ابتدا یک نسخه 32 بیتی بود، اما از آن زمان تا کنون به یک سیستمعامل 64 بیتی تبدیل شده است. برخلاف سیستمعامل IOS سیسکو، سیستمعاملNX-OS از فضای حافظه مشترکی استفاده نمیکند اما از چند پردازش متقارن با ورودی، خروجی یا مسیر مشترک پشتیبانی میکند. همچنین امکان چندوظیفه ای نوبه ای Preemptive Multitasking 3 را فراهم میکند که به یک فرایند با درجه اهمیت بالاتر اجازه میدهد تا پیش از یک فرایند با درجه اهمیت پایینتر اجرا شود.
NX-OS بر روی هسته لینوکس ساخته شده است و به طور طبیعی از زبان Python برای ایجاد اسکریپت در سوئیچهای Cisco Nexus پشتیبانی میکند. علاوه بر این، دارای چندین ویژگی دسترسیپذیری پیشرفته است و همه ویژگیهای خود را به یکباره اجرا نمیکند. در عوض، میتوانید مشخص کنید که کدام ویژگی را میخواهید فعال کنید. حذف اجرای ویژگیهای غیرضروری، حافظه و پردازنده را برای ویژگیهایی که میخواهید آزاد میکند. بااینحال، در حوزه پیکربندی، شباهتهای زیادی بین NX-OS و سیستمعامل IOS سیسکو وجود دارد.
سیستمعاملIOS-XRسیسکو
این سیستمعامل که در اصل برای عملکرد 64 بیتی طراحی شده بود، بسیاری از امکانات پیشرفته موجود در سیستمعامل NX-OS را ارائه میدهد (مانند پردازش چندگانه متقارن، فضاهای حافظه اختصاصی، و فعالکردن خدمات موردنیاز). بااینحال، درحالیکه سیستمعامل NX-OS بر روی هسته لینوکس ساخته شده، سیستمعامل IOS-XR بر مبنای توسعه داده شده است.میکرو کرنل نوترینو QNX4Neutrino Microkernel مشابه یونیکس است و اکنون تحت مالکیت شرکت بلکبری است.
یکی از ویژگیهای سیستمعامل IOS-XR که در سیستمعامل NX-OS یافت نمیشود، امکان داشتن نمونهای از سیستمعامل است که چندین کیس را کنترل میکند. همچنین، ازآنجاییکه سیستمعامل IOS-XR محیطهای ارائهدهنده خدمات را هدف قرار میدهد، از رابطهایی مانند DWDM و Packet over SONET پشتیبانی میکند.
در حالی که پیکربندی IOS-XR تا حدودی شباهت به ورژن قدیمی IOS سیسکو دارد، تفاوتها در مقایسه با تفاوتهای موجود در NX-OS بسیار محسوستر هستند. مثلاً هنگامی که واردکردن دستورات پیکربندی به پایان رسید، باید تغییرات خود را برای اجراییشدن آنها و قبل از خروج از حالت پیکربندی اعمال کنید.
نمونههای پیکربندی
برای نمایش برخی تنظیمات اولیه در این سه سیستمعامل، موارد زیر را در نظر بگیرید. این دستورات روی روتر سیستمعامل IOSسیسکو، سوئیچ NX-OS و نمونه های روتر IOS-XR که در Cisco VIRL اجرا میشوند داده شده است. هر یک از مثالهای زیر نسخه فعلی روتر یا سوئیچ سیستمعامل را نشان میدهند. سپس وارد حالت پیکربندی سراسری میشویم و نام میزبان روتر یا سوئیچ را تغییر میدهیم و به دنبال آن یک رابط Loopback 0 ایجاد میکنیم، بعد از اختصاص یک آدرس IP ، به حالت دسترسی بازمیگردیم و دستور کوتاه نمایش IP را صادر میکنیم.
هنگام تخصیص آدرسهای IP به رابطهای Loopback در سیستمهای سختافزاری، توجه داشته باشید که سیستمعامل IOS سیسکو نیاز دارد که عدد پوشش زیر شبکهSubnet Mask 5 با نماد اعشاری نقطهدار وارد شود، درحالیکه NX-OS و IOS-XR از واردکردن پوشش زیر شبکه بهصورت اسلش پشتیبانی میکنند (یعنی استفاده از /32 بهجای استفاده از 255.255.255.255). همچنین توجه داشته باشید که قبل از خروج از حالت پیکربندی باید دستور commit را در IOS-XR اجرا کنید. همچنین، تنها زمانی که آن فرمان را صادر میکنیم، جدیدترین پیکربندی نام میزبان اعمال میشود.
https://faradsys.com/wp-content/uploads/2022/08/differences-between-cisco-ios.jpg394700فاطمه هاشمیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngفاطمه هاشمی2022-08-07 15:30:202022-08-14 10:07:08مقایسه سیستم عامل های IOS، NX-OS و IOS-XR
تفاوت بین TRADITIONAL WAN و SD-WAN چیست و کدامیک برای حرفه شما مناسبتر است؟
روی آوردن به شبکه SD-WAN برای کسبوکارها در سراسر جهان در حال گسترش است. بر اساس تحقیقات شرکت Adroit Market Research، پیشبینی میشود که بازار جهانی SD-WAN تا سال 2028 به 26 میلیارد دلار برسد.
بااینحال، استفاده از فناوری TRADITIONAL WAN هنوز روشی معتبر و قابلاعتماد برای ارائه و دریافت خدمات شبکه است. در برخی موارد، یک رویکرد ترکیبی قابلاجرا کاربردیترین روش است. این امر درواقع به نیازها و موقعیت منحصربهفرد هر سازمان بستگی دارد.
فارغ از اینکه سازمان شما همچنان از فناوری TRADITIONAL WAN استفاده کند یا بهطور کامل به SD-WAN تغییر کاربری داده باشد و یا از ترکیبی از این دو بهره ببرد، در این مقاله میتوانید تمامی اطلاعات موردنیاز در مورد این دو فناوری را به دست آورید.
TRADITIONAL WAN چیست؟
فناوری TRADITIONAL WAN مدتهاست که برای زیرساختهای شبکههای فناوری اطلاعات، صدا و داده مورد استفاده قرار گرفته است. یک TRADITIONAL WAN که برای اتصال چندین شرکت استفاده میشود، شبکههای محلی(LAN) را از طریق روترها و شبکههای خصوصی مجازی (VPN) به یکدیگر متصل میکند.
شبکههای TRADITIONAL WAN بیشتر به اتصالات سوئیچینگ با کمک برچسبزنی چند پروتکل اختصاصی (MPLS) برای ارائه اتصالات امن و مستقیم برای جریان ترافیک شبکه قابلاعتماد و کارآمد متکی هستند. با استفاده از این تکنیک میتوانید ترافیک صوتی، ویدیویی و داده را در شبکه خود اولویتبندی کنید.
SD-WAN
ازآنجاییکه ابزارها و برنامههای حیاتی برای کسبوکار، مجازی شدهاند، ترافیک شبکه افزایشیافته است و به اتصالات MPLS یک TRADITIONAL WAN فشار زیادی وارد میشود. SD-WAN یک رویکرد منحصربهفرد برای شبکههای گسترده است زیرا فناوریهای TRADITIONAL WAN مانند MPLS اختصاصی را با اتصالات باند پهن ارزانتر ترکیب میکند.
شبکههای SD-WAN دید وسیعی از کل شبکه WAN و توانایی اولویتبندی ترافیک شبکه در سراسر اتصالات مختلف را به سازمانها ارائه میدهند. SD-WAN ترافیک را بررسی میکند و در لحظه بهترین مسیر را برای هر َپکِت داده انتخاب میکند.
با SD-WAN، سازمانها میتوانند تمام دفاتر خود را به یک شبکه مرکزی در محیط رایانش ابری متصل کنند که کنترل و انعطافپذیری بیشتری را به همراه دارد.
معیار مقایسه SD-WAN با TRADITIONAL WAN
معیارهایی که برای مقایسه SD-WAN و TRADITIONAL WAN مورد استفاده قرار می گیرند به شرح زیر است:
قابلیت اطمینان و اولویتبندی
بهطورکلی، TRADITIONAL WAN هایی که بر روی MPLS اجرا میشوند، کیفیتی فوق العاده از خدمات (QoS)را ارائه میدهند، زیرا با جداسازی پَکِت ها بهصورت مجازی عملاً از Packet Loss جلوگیری میکنند. بیشتر اوقات، این مورد از طریق یک اتصال مدار حامل رده اجرا میشود. بااینحال، نکتهای که باید مدنظر قرارداد این است که پهنای باند MPLS از این نوع، معمولاً گرانتر است.
تعیین اینکه کدام ترافیک اولویت بیشتری دارد ضروری است و به سازمانها کمک میکند تا مطمئن شوند تماسهایشان قطع نمیشود. فناوری TRADITIONAL WAN امکان اولویتبندی را فراهم میکند و میتواند امکان پیشبینی و قابلیت اطمینان ترافیک را به شما ارائه دهد.
تحقیقات نشان میدهد که هزینههای اینترنت را میتوان با SD-WAN کاهش داد. دلیل این امر این است که برای ارتقای پهنای باند خود و همچنین امکان ترکیب و تطبیق لینکهای شبکه به روشی مقرونبهصرفه، با توجه به نوع محتوا و اولویت، نیازی به پرداخت هزینه اضافه ندارید. SD-WAN میتواند روی 4G LTE و پهنای باند اینترنت اجرا شود که معمولاً هزینه کمتری نسبت به خدمات ارائهشده از طریق شبکه MPLS دارد.
SD-WAN به شما این امکان را میدهد که مهمترین ترافیک داده خود را از طریق لینک شبکه مناسب همراه با دهها گزینه اولویتبندی برنامه ارسال کنید. این امر منجر به تأخیر به میزان کم یا عدم وجود تأخیر و Packet Loss میشود. علاوه بر این، اگر قطعی رخ دهد، ترافیک شما فوراً جایگزین اتصال دیگری میگردد.
امنیت
TRADITIONAL WAN کاملاً امن در نظر گرفته میشود. َپکِتهایی که از طریق اتصال MPLS ارسال میشوند خصوصی هستند و فقط بااتصال MPLS مقصد قابلمشاهده میباشند و امکان ارتباط ایمن بین سایتها را فراهم میکنند.
SD-WAN با ارائه رمزگذاری سرتاسری از طریق اتصال (VPN) ترافیک داده شمارا ایمن نگه میدارد. این فناوری همچنین به شما این امکان را میدهد که بهراحتی لایههای امنیتی جانبی مانند فایروال و خدمات مرتبط را برای مدیریت یکپارچه تهدید، پیادهسازی و ادغام کنید.
کنترل و مقیاسپذیری
اعمال تغییرات در TRADITIONAL WAN، باید بهصورت دستی انجام شود. این فرآیند نیازمند زمان طولانیتری است و کارایی شرکتهای تازه تأسیس، بهویژه آنهایی که شعبات متعددی دارند را پایین میآورد.
درصورتیکه با یک ارائهدهنده موفق خدمات همکاری داشته باشید SD-WAN را بهعنوان یک تکنولوژی نرمافزاری میتوان متناسب با گسترش سازمان به سهولت توسعه داد.
SD-WAN در مقایسه باWAN معمولی
SD-WAN روی ترکیبی از اتصالات شبکه اجرا میشود که میتواند به کاهش هزینه کمک کند.
SD-WAN گزینههای اولویتبندی برنامهها را ارائه میدهد و دادههای مهم را از طریق مناسبترین لینک شبکه ارسال میکند.
SD-WAN از رمزگذاری و VPN برای اتصالات شبکه سرتاسری ایمن استفاده میکند.
بهروزرسانی و توسعه SD-WAN آسان است.
TRADITIONAL WAN ها در MPLS، QoS بینظیری را ارائه میدهند، اما ممکن است گرانتر باشند.
TRADITIONAL WAN قابلیت اطمینان و پیشبینی را با اولویت ترافیک بحرانی مانند صدا و تصویر، ارائه میدهد.
اتصال Traditional WAN’s MPLS بسیار امن است.
تغییرات در TRADITIONAL WAN باید بهصورت دستی انجام شود.
درنهایت، انتخاب بین TRADITIONAL WAN و SD-WAN به وضعیت سازمان و زیرساخت فعلی شما بستگی دارد. بسیاری از سازمانها در حال روی آوردن به SD-WAN هستند، اما شرایط متفاوت است. این موضوع به اهداف کوتاهمدت و نیازهای بلندمدت هر سازمان بستگی دارد.
https://faradsys.com/wp-content/uploads/2022/07/sd-vs-traditionalp.jpg520780فاطمه هاشمیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngفاطمه هاشمی2022-07-31 15:58:172022-07-31 15:58:17مقایسه شبکه SD-WAN و WAN
حفظ امنیت اطلاعات در عصر اطلاعات پارامتر مهمی است که دغدغه اصلی بسیاری از مدیران است و باید به آن توجه ویژه ای کرد. برای اینکه بتوانیم از اطلاعاتمان محافظت کنیم، به شناخت راه های مقابله با حملات سایبری، بد افزارها و آسیب پذیری ها نیاز داریم. از طرفی این موضوع که در معرض کدام یکی از آنها هستیم هم می تواند به ما کمک کند. ادامه نوشته
https://faradsys.com/wp-content/uploads/2020/08/cyber-attack-types-low-1.jpg6301008عباس اشرفیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngعباس اشرفی2020-08-08 11:00:562020-08-11 01:25:51انواع حملات سایبری که ما را تهدید می کنند
اولین راه مقابله با بدافزارها و حملات سایبری، استفاده از فایروالمی باشد. بخش زیادی از بد افزارها و malware ها در طول سال های گذشته، توسط فایروال ها دفع و خنثی شده اند. برای نمونه برخی از بزرگترین نفوذهای چند سال اخیر از جمله WannaCry، Nyetya و VPNFilter را در نظر بگیرید؛ حمله WannaCry در تاریخ 12 ماه می 2017 در صدر اخبار جهانی قرار گرفت. در حالیکه مشتریانفایروال NGFW سیسکو از مدتها پیش در تاریخ 14 ماه مارس در برابر آن حفاظت می شدند، بدون اینکه خودشان مجبور به انجام کاری باشند. از این رو شناخت انواع فایروال و کاربرد آنها و انتخاب فایروال مناسب مسئله ای مهم برای مدیران شبکه است. ادامه نوشته
https://faradsys.com/wp-content/uploads/2020/08/firewall_types.jpg8021280عباس اشرفیhttps://faradsys.com/wp-content/uploads/2020/05/logo-Farad_op_f_2.pngعباس اشرفی2020-08-01 14:59:102020-08-10 14:19:05انواع فایروال هایی که باید آن ها را بشناسید